
Introducing Runpod Overdrive: Get more out of the inference you're already running
Introducing Runpod Overdrive: optimization for your model, your workload.
All
Blog
We tested four models across sixteen workload profiles. Here's exactly what we measured and how.


Runpod Overdrive is an inference optimization engine, purpose-built to push models to peak speed. It’s designed for teams that demand the best performance at the lowest cost, and don't want to spend endless engineering cycles chasing it. We’ve done the optimization so you can stay focused on building.
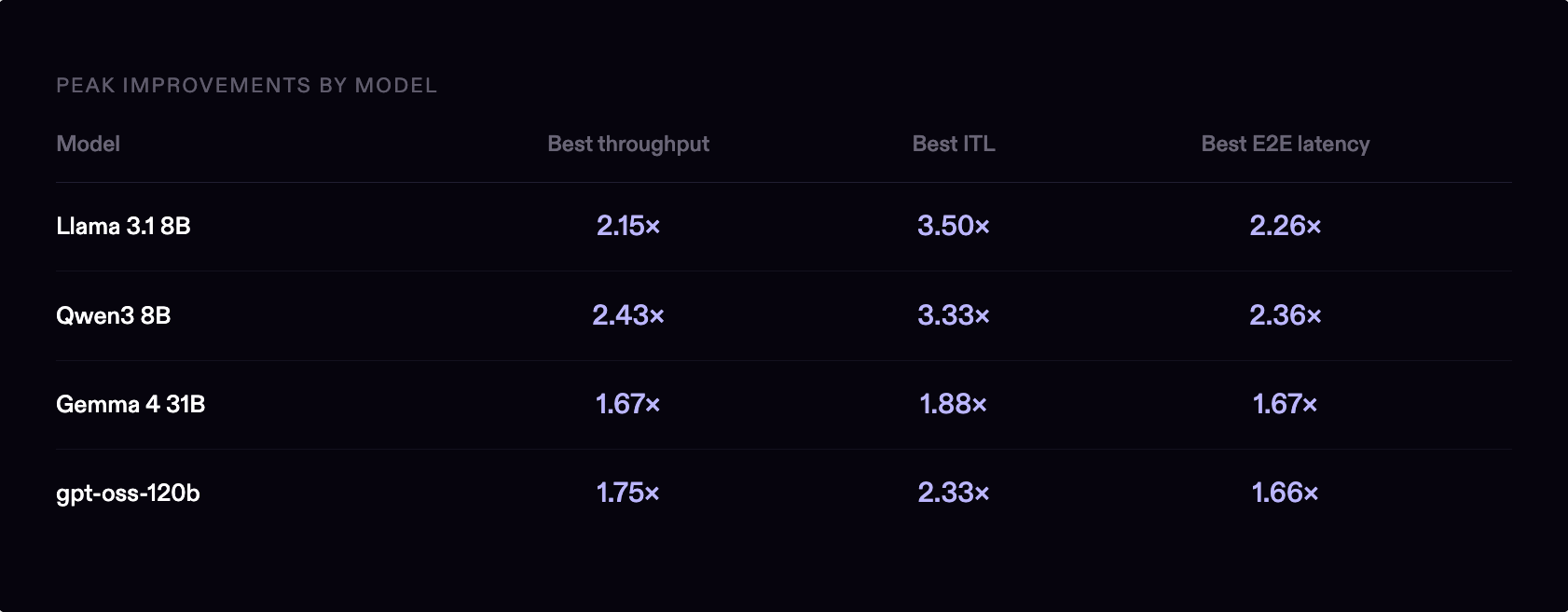
The result: a median 36% reduction in cost per million output tokens compared to baseline configurations on the same H100 SXM 80GB GPUs, with no compromises on quality.
Most inference optimization stops at the model. Overdrive goes further: every configuration is tuned to the model and the workload profile serving it. A chatbot, a RAG pipeline, a code generation service, and a long-form generation job have fundamentally different performance characteristics, even on the same model, the same GPU. Treating them the same leaves performance on the table.
The benchmark results below cover four categories: spanning small dense models, a mid-size model, and a large MoE, chosen because they collectively represent the range of architectures and serving challenges that matter most in production.
Each model ran across four workload profiles designed to reflect real traffic patterns: chatbot, RAG, code generation, and long-form generation. 300 requests each, fixed seed, same infrastructure, same worker counts. The only variable was the inference configuration.
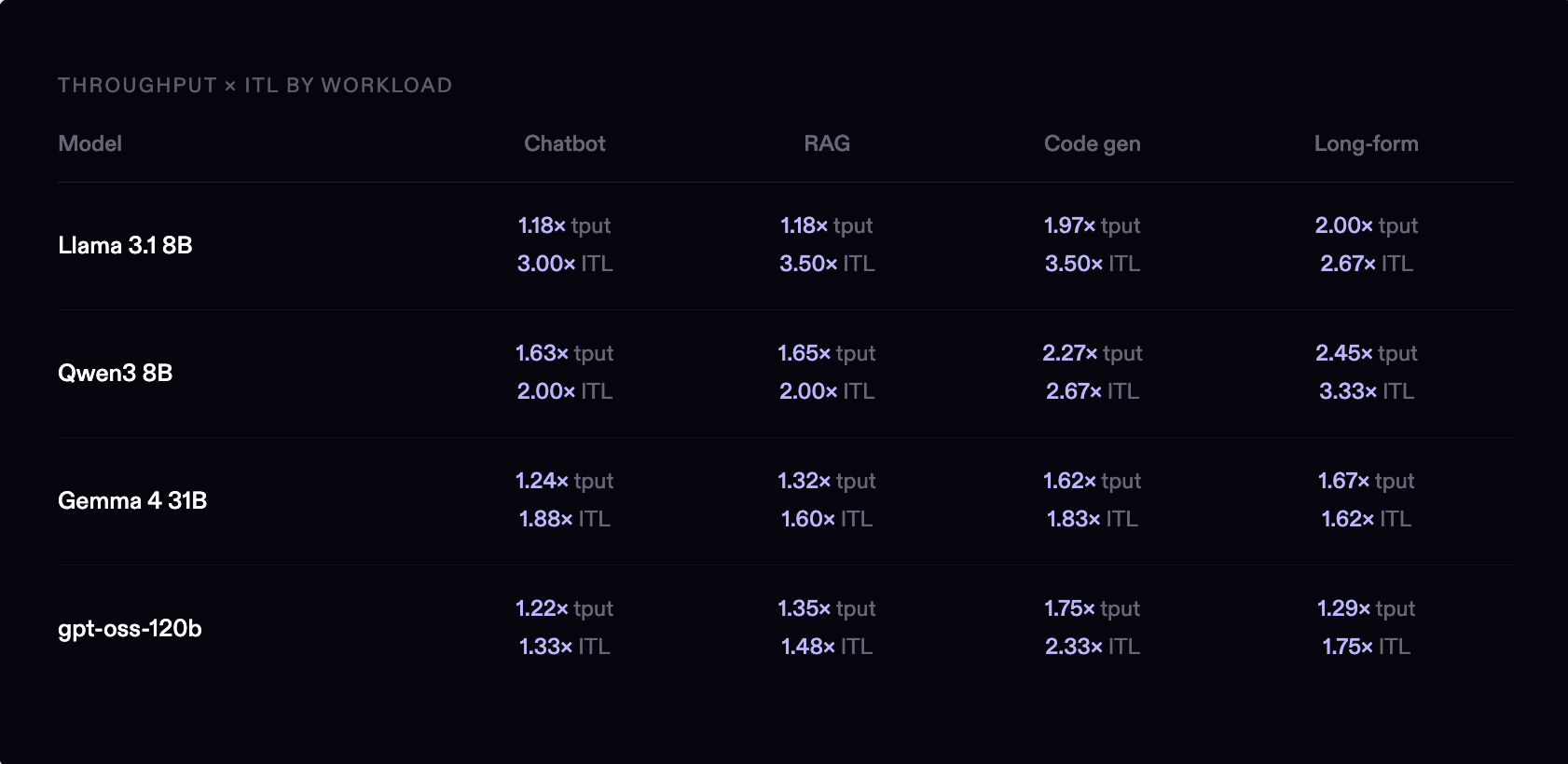
Throughput scales with decode ratio. The more output tokens a workload generates relative to input, the larger the gain. On chatbot workloads, Overdrive delivers 1.18-1.63× more requests per second. On long-form generation, where the model spends most of its time in the decode phase, that reaches 2.00–2.45× on dense 8B models.
Token streaming is the most consistent win. Inter-token latency improved across every model and every workload, this is the metric users feel most directly. Dense 8B models saw 2-3.5× faster ITL; Gemma 4 31B saw 1.6-1.88×; gpt-oss-120b saw 1.33-2.33×.
TTFT is a trade-off, but E2E latency tells the full story. On some workloads TTFT increases slightly, but end-to-end latency drops significantly. On Llama 3.1 8B running code generation, TTFT increased by 278ms while end-to-end latency dropped by 4.4 seconds. On long-form workloads, the spread is even wider: TTFT up ~190ms, end-to-end down more than 10 seconds.
Quality holds. We validated output quality across all configurations using standardized benchmarks. Near lossless eval scores were observed across all models and workloads, which is ideal for production deployments.
Efficient LLM serving is a design problem across four layers: compute, memory bandwidth, memory capacity, and scheduling. Default engines like vLLM are built to work anywhere, any model, any GPU, any workload. That generality is the point. It's also the ceiling.
Overdrive is built on a continuously-evolving stack of optimizations drawn from the research community and our own in-house expertise. This spans speculative decoding using Eagle3 speculator heads trained per target model, workload-aware memory management, and traffic-sensitive scheduling parameters. We're also actively experimenting with DFlash, a block-diffusion drafter architecture that generates candidate tokens in parallel rather than sequentially.
These techniques aren't new in isolation. The returns come from how they're tailored for a specific model and traffic pattern, and from the discipline of revisiting that composition as models and workloads evolve. The right configuration for a dense 8B model at high chatbot concurrency looks very different from what's needed for a 120B MoE handling long-form generation with tight memory margins. Neither is static: traffic changes, context lengths shift, new models arrive. The configuration is a living part of the system.
Every benchmark in this post ran on Runpod Serverless on H100 SXM 80GB GPUs. Overdrive is the inference optimization layer; Runpod Serverless is the infrastructure beneath it: pay-per-use, no reserved capacity, autoscaling to meet load.
That combination means you're not paying for idle compute, and you're not running a generic configuration on top of it. Overdrive is live today across Runpod Serverless, with optimized configurations rolling out continuously as we expand model coverage.
Overdrive is available now for teams running popular LLM architectures running production inference on Runpod Serverless. To get your workload evaluated, talk to our team.
Learn more about Runpod Overdrive
Blog Posts
Introducing Runpod Overdrive: optimization for your model, your workload.
.jpeg)
Whether you're already running production endpoints on Runpod or you're sizing us up for the first time, here's a plain-language tour of what Runpod Serverless does today, why it's faster and cheaper than it was six months ago, and how to deploy your first endpoint in minutes.

Shift from stateless inference to stateful architectures to resolve infrastructure bottlenecks like memory management, concurrency limits, and runaway jobs in production AI agents.
