Serverless
Dedicated Serverless GPU API endpoints
Runpod Serverless runs AI inference with sub-200ms FlashBoot cold starts, per-second billing, and scale to zero. Deploy any containerized model as an autoscaling GPU endpoint without managing servers.

Bring your container.
Deploy any container with full control and flexibility.
Network storage.
Persistent, high-speed storage that scales with your workloads.
Global regions.
Deploy closer to your users with low-latency regions worldwide.

What is Runpod Serverless?
Serverless GPU endpoints run containerized inference workloads behind an API and scale workers based on demand. Use Runpod Serverless when requests arrive in bursts, when you want to avoid idle compute, or when your team wants to deploy model inference without managing GPU servers.
How it Works
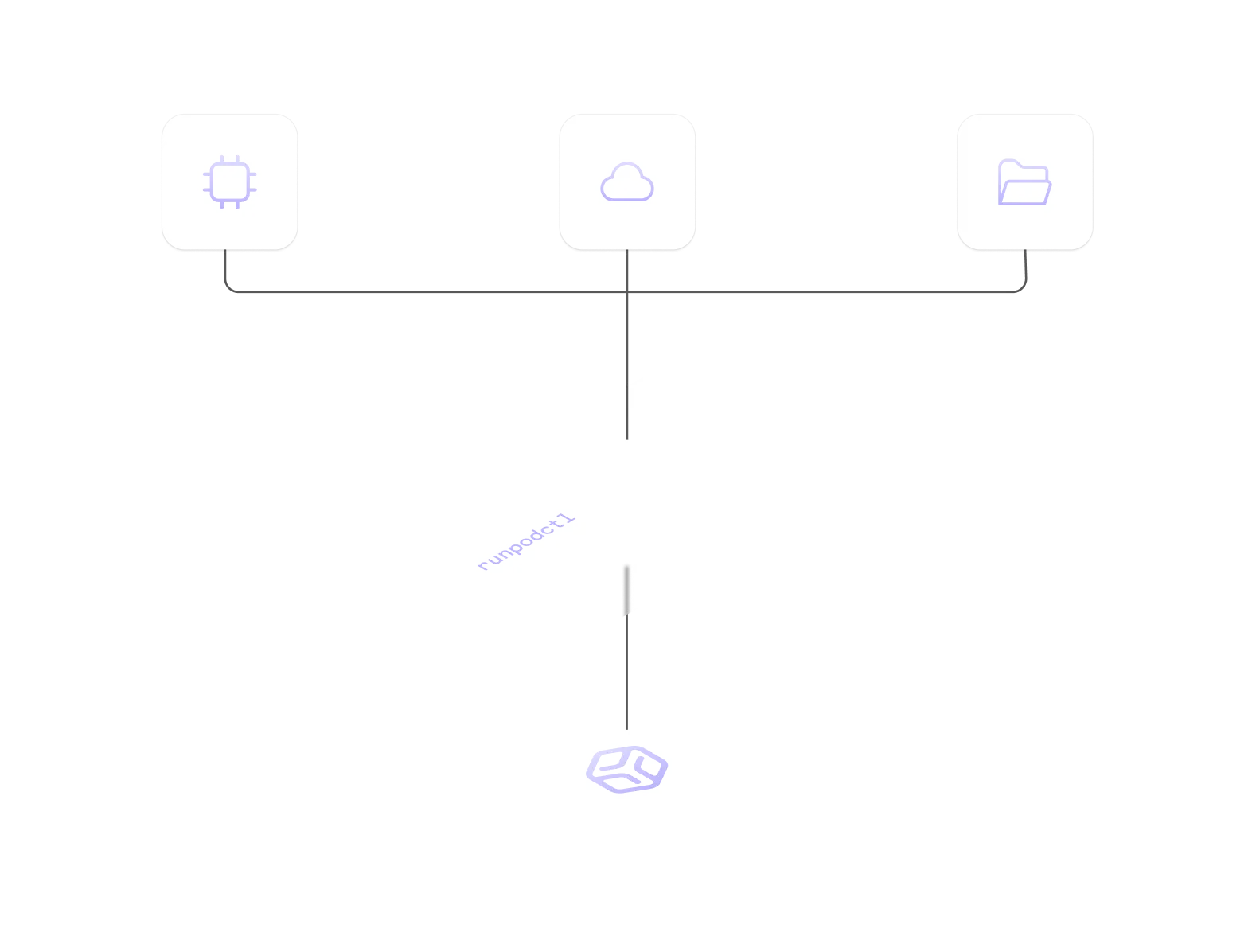
From code to cloud.
Deploy, scale, and manage your entire stack in one streamlined workflow.



Features
Effortlessly scale AI inference.
When every element clicks, deploying, scaling, and optimizing becomes pure magic.
Flexible runtimes.
Run AI/ML workloads with support for a wide range of languages, frameworks, and custom configurations.
Zero cold starts.
Pre-warmed functions guarantee an immediate response, eliminating all initial latency delays.
Use Cases
What teams build with serverless.
See how teams are building AI apps, automation, and analytics. Without managing infrastructure.




"The Runpod team has clearly prioritized the developer experience to create an elegant solution that enables individuals to rapidly develop custom AI apps or integrations while also paving the way for organizations to truly deliver on the promise of AI."
Amjad Masad
"Runpod is the only place I can deploy high-end GPU models instantly. No sales calls, no rate limits, no nonsense."
Daniel Chang
“The main value proposition for us was the flexibility Runpod offered. We were able to scale up effortlessly to meet the demand at launch.”
Josh Payne
“Runpod helped us scale the part of our platform that drives creation. That’s what fuels the rest. Image generation, sharing, remixing. It starts with training.”
Matty Shimura
Serverless
Serverless GPU endpoints run containerized inference workloads behind an API and scale workers based on demand. Use Runpod Serverless for request-driven inference when your team wants to deploy models without managing GPU servers.
Building agents? Explore GPU endpoints for AI agents.
Running this at company scale? See Serverless for enterprise.
FAQs
Questions? Answers.
Serverless, simplified. Clear answers on running your code without the fuss.
Runpod’s serverless GPUs eliminate cold starts with always-on, pre-warmed instances, ensuring low-latency execution. Unlike traditional serverless solutions, Runpod offers full control over runtimes, persistent storage options, and direct access to powerful GPUs, making it ideal for AI/ML workloads.
Runpod supports Python, Node.js, Go, Rust, and C++, along with popular AI/ML frameworks like PyTorch, TensorFlow, JAX, and ONNX. You can also bring your own custom runtime via Docker containers, giving you full flexibility over your environment.
Runpod uses active worker pools and pre-warmed GPUs to minimize initialization time. Serverless instances remain ready to handle requests immediately, preventing the typical delays seen in traditional cloud function environments.
Runpod allows deployments directly from GitHub, with one-click launches for pre-configured templates. For rollback management, you can revert to previous container versions instantly, ensuring a seamless and controlled deployment process.
Runpod integrates with webhooks, APIs, and custom event triggers, enabling seamless execution of AI/ML workloads in response to external events. You can set up GPU-powered functions that automatically run on demand, scaling dynamically without persistent instance management.
Runpod offers a comprehensive monitoring dashboard with real-time logging and distributed tracing for your serverless functions. Additionally, you can integrate with popular APM tools for deeper performance insights and efficient debugging.
Clients
Trusted by today's leaders, built for tomorrow's pioneers.
Engineered for teams building the future.
10,100,100,100
Requests since launch & 1M+ developers worldwide

